Automatically Finding A Short Twitter Username
I had a chat with a friend the other day, and he mentioned off-hand that in his life there is a very unique problem - lack of a short username for their Twitter account. Seems like everything good is already taken, which makes sense considering that Twitter itself is 14 years old. You can bet that in 14 years, a lot of people did get very creative with usernames. Or did they?
I set out to figure out a way to automate this process. I could throw a dictionary at the problem, or just literally generate every word out of a combination of characters, and see what’s available and what’s not by going to https://twitter.com/{letter_combination} and see which pages exist. This could work in theory, but there is just so much variability about the process, and zero insights on whether the account is actually available, because there could be several reasons why the account is not displayed.
Manual iteration is going to take some time - assuming that I can check one username every 3 seconds, that puts 1000 usernames at 3000 seconds in ideal conditions. So almost an hour of typing and seeing the results. Also, I don’t know about all other engineers, but “ideal conditions” doesn’t quite apply to me, because I will have typos and at some point will need coffee. Besides, if I take all possible combinations of 5 letter words, that puts me at 11,881,376 words to try. So this approach is not quite workable.
So maybe there is a better way? Twitter already does this when I try to change the username, and a little bit API digging uncovers the big prize:
https://twitter.com/i/api/i/users/username_available.json?username={USERNAME}
Coolio, if I make requests against this API, I should be able to quickly pinpoint what’s available and what is not. Here’s a Python script to do this, where I throw a list of generated words at the problem:
import requests
import json
import configparser
from datetime import datetime
import time
import itertools
SLEEP_PERIOD = 900
MIN_WORD_LENGTH = 5
MAX_WORD_LENGTH = 5
words = []
acceptable_words = []
valid_words = []
words_scanned = 0
config = configparser.ConfigParser()
config.read('config.ini')
with open("words_generated.txt", "r") as word_file:
words = word_file.read().splitlines()
print(f'[info] Loaded {len(words)} words.')
print(f'[info] Searching words between {MIN_WORD_LENGTH} and {MAX_WORD_LENGTH} characters.')
acceptable_words = [x for x in words if len(x) >= MIN_WORD_LENGTH and len(x) <= MAX_WORD_LENGTH]
print(f'[info] Loaded {len(acceptable_words)} acceptable words.')
target_keywords = [x for x in acceptable_words if x.startswith('xp')]
words = []
acceptable_words = []
print(len(target_keywords))
for word in target_keywords:
while True:
url = f'https://twitter.com/i/api/i/users/username_available.json?username={word}'
headers = {
'authorization': 'SOME_TOKEN',
'Cookie': 'COOKIE_VALUE',
'x-csrf-token': 'CSRF_TOKEN_VALUE',
'x-twitter-auth-type': 'OAuth2Session',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:83.0)',
'x-twitter-active-user': 'yes',
'TE': 'Trailers',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://twitter.com/settings/screen_name',
'x-twitter-client-language': 'en',
'Host': 'twitter.com',
'Accept-Language': 'en-US,en;q=0.5'
}
response = requests.request('GET', url, headers=headers)
try:
if response.status_code == 200:
raw_data = json.loads(response.text)
if raw_data["valid"] == False:
break
else:
valid_words.append(word)
break
elif response.status_code == 429:
print(f'[info] Words scanned: {words_scanned}. Valid words found: {len(valid_words)}. Last response code: {response.status_code}. Last word checked: {word}')
print(f'[info] Looks like we are rate limited. Sleeping for 10 minutes. Started at {datetime.now().isoformat()}.')
print('[info] Valid usernames:')
for valid_word in valid_words:
print(valid_word)
time.sleep(SLEEP_PERIOD)
continue
else:
print(f'[info] Error. Status code: {response.status_code}')
except Exception as ex:
print(ex)
break
words_scanned = words_scanned + 1
print(f'[info] Words scanned: {words_scanned}. Valid words found: {len(valid_words)}. Last response code: {response.status_code}. Last word checked: {word}', end="\r", flush=True)
print('[info] Valid usernames:')
for valid_word in valid_words:
print(valid_word)
In this case, I took the headers word-for-word from the HTTP request in the browser, just to make sure that my script is as close to the expected environment as possible. Running it, I am able to see what aliases are available - there is a good amount of 5 character IDs still up for grabs (that’s the minimum for Twitter these days)!
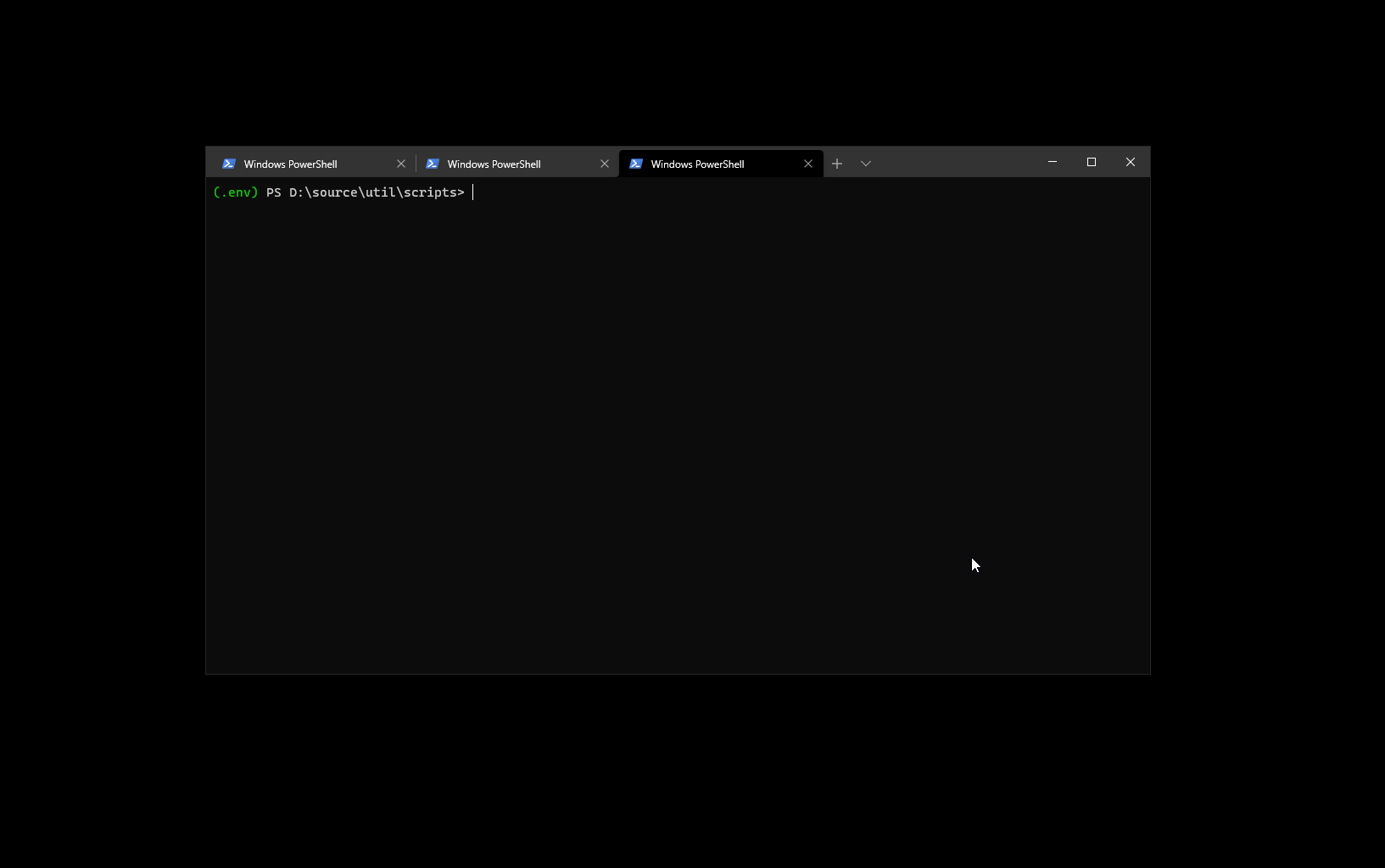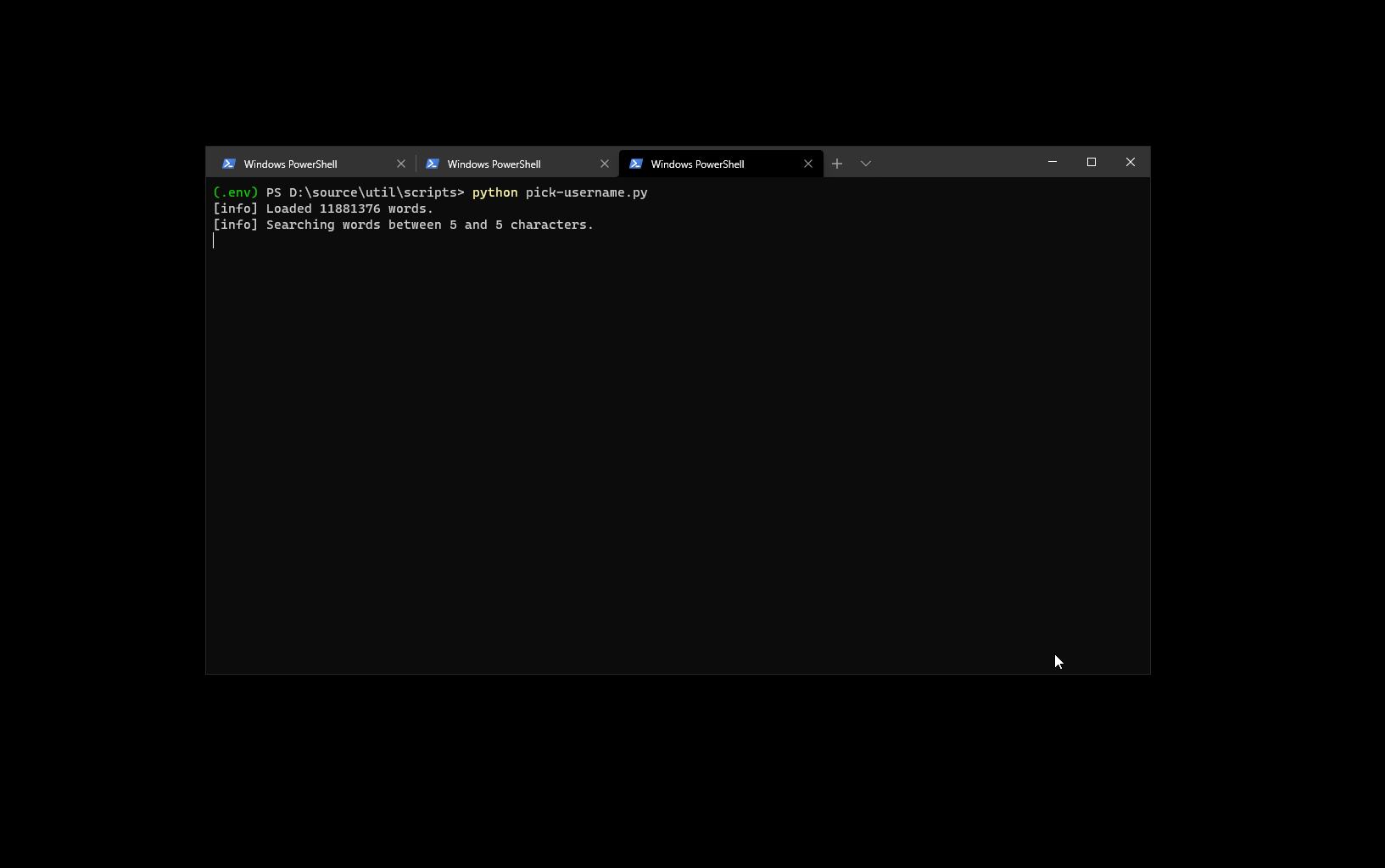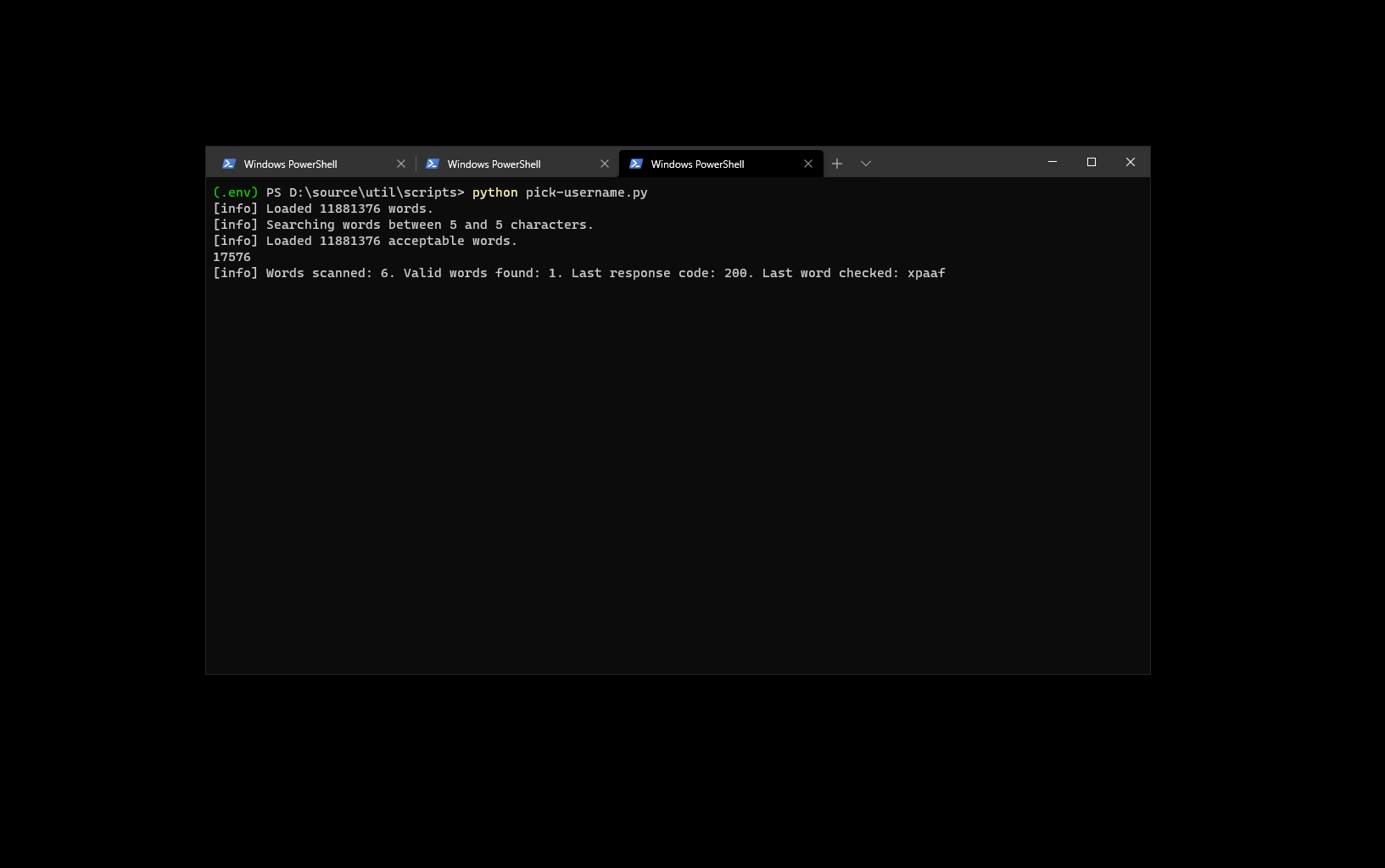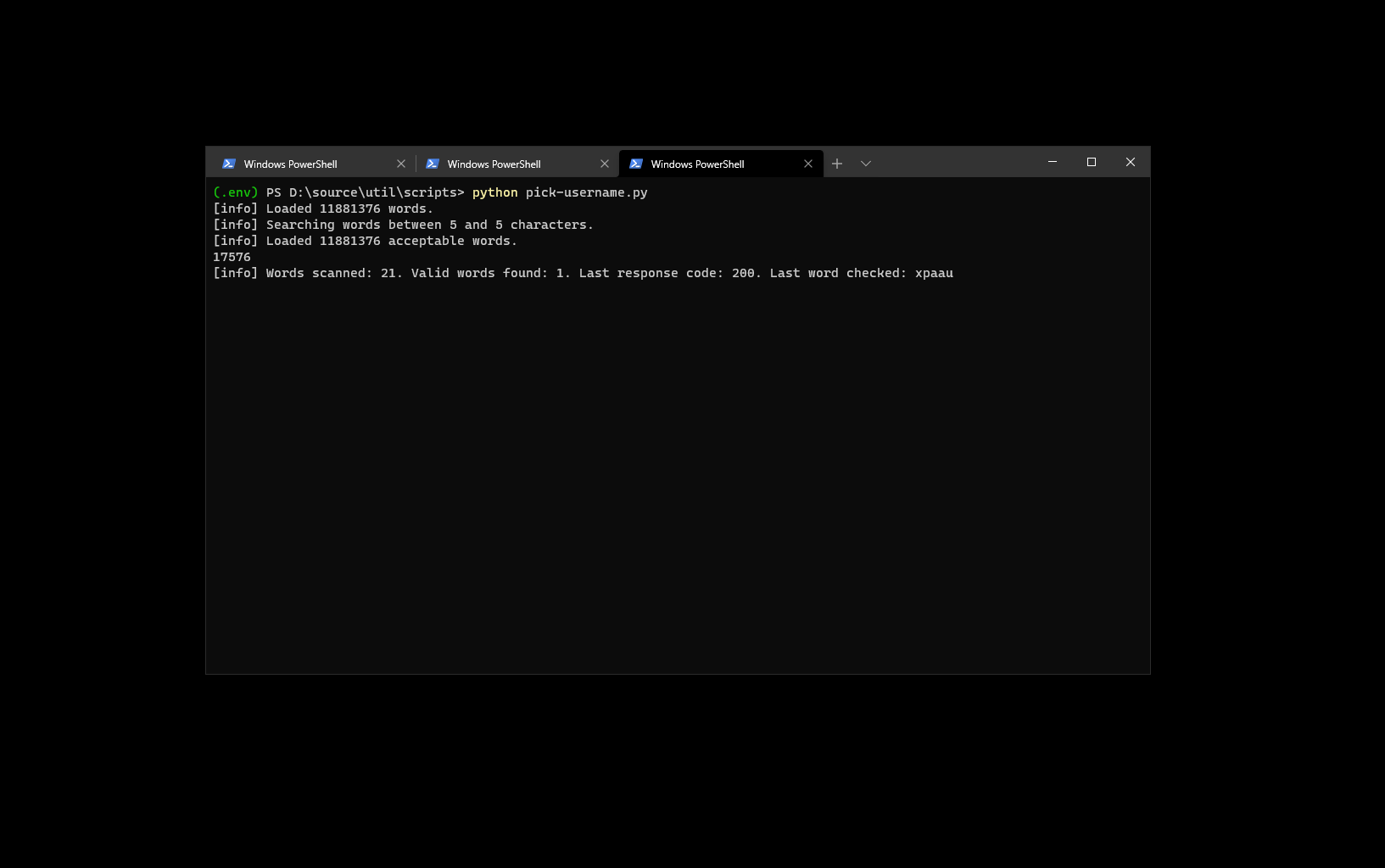
With the script, you can check roughly 500 combinations every 15 minutes. And if you are one of those people that is into usernames that start with 0x (say, if you just like HEX codes so much), there are plenty of 5-letter usernames starting with 0x, like 0x02b or 0x0fd. You can also create custom word combinations based on rules you have in mind, such as “all 6 character words that start with xp” and drop them in the text file that is read at the beginning of this script, and you’re golden.
Good luck finding the perfect Twitter username!